Inside OpenAI's In-House Data Agent: From Question to Insight in Minutes
OpenAI built a bespoke internal AI data agent that lets any employee - not just data engineers - go from natural language question to verified insight in minutes. The agent is powered by GPT-5.2, uses Codex to deeply understand table semantics from source code, retrieves context via RAG over 70k datasets (600 PB), and continuously self-improves through a layered memory system. The post breaks down its six-layer context architecture, conversational reasoning loop, eval-driven quality assurance, and key lessons in agent design.
Ready to ace your system design interview?
This article is just one piece. SWE Quiz gives you structured, interview-focused practice across every topic that comes up in senior engineering rounds.
- 1,000+ quiz questions across system design and ML/AI
- Spaced repetition to lock in what you learn
- Full case study walkthroughs of real interview topics
- Track streaks, XP, and progress over time
TL;DR
- OpenAI's internal data platform has over 3.5k users, 70k datasets, and 600 PB of data - finding the right table and writing correct SQL was the biggest bottleneck.
- The agent uses six layers of context: table usage metadata, human annotations, Codex-derived code enrichment, institutional knowledge (Slack/Docs/Notion), a self-learning memory system, and live runtime queries.
- Codex enrichment is the secret weapon - by crawling the pipeline code that produces each table, the agent learns what the data actually contains, not just its schema shape.
- A continuously learning memory system stores corrections and non-obvious filters, so the agent improves with every interaction instead of repeating mistakes.
- Lessons learned: fewer tools beat more tools (less ambiguity), high-level guidance outperforms prescriptive prompts, and a table's true meaning lives in the code that produces it.
Why this matters for interviews
AI agents are becoming a core system design topic. This post gives you a real production architecture for RAG-based data agents at scale - including how to layer context sources, build self-improving memory, evaluate agent quality, and handle the security model. Use these patterns when asked to design an AI assistant, a data platform, or any system that combines LLMs with structured data retrieval.
Breakdown
1.Why a custom data agent? The table discovery bottleneck
OpenAI's data platform serves 3.5k internal users across 70k datasets totaling 600 petabytes. The hardest part of data analysis wasn't writing queries - it was finding the right table. Many tables look similar but differ in subtle ways: one includes logged-out users, another doesn't; fields overlap but have different semantics. Analysts spent hours figuring out which table to use before writing a single line of SQL. Even with the right tables, producing correct results required reasoning about joins (many-to-many joins silently duplicate rows), filter pushdown order, and null handling. A 180-line SQL statement might look correct but produce wrong numbers because of a subtle join condition. OpenAI built a bespoke agent - not a generic chatbot - tailored to their specific data, permissions, and workflows to eliminate this bottleneck.
Interview angle: When designing a data platform, interviewers probe whether you understand the human bottlenecks, not just the technical ones. "Finding the right table" is a metadata discovery problem - and it's where most data platforms fail. Strong candidates mention data catalogs, semantic search over schemas, and lineage tracking as solutions.
2.The six-layer context architecture
The agent's accuracy depends entirely on context quality. Without it, even GPT-5 produces wrong results - misestimating user counts or misinterpreting internal terminology. OpenAI designed six layers of context, each filling a gap the previous layers can't cover. Layer 1 (Table Usage): schema metadata like column names and types plus historical query patterns that reveal how tables are typically joined. Layer 2 (Human Annotations): curated descriptions from domain experts capturing business meaning, intent, and known caveats that can't be inferred from schemas. Layer 3 (Codex Enrichment): code-level definitions derived by crawling the pipeline source code with Codex - revealing what data a table actually contains, its update frequency, granularity, and scope. Layer 4 (Institutional Knowledge): documents from Slack, Google Docs, and Notion containing launch context, incident reports, internal codenames, and canonical metric definitions. Layer 5 (Memory): corrections and learnings saved from previous conversations that persist across sessions. Layer 6 (Runtime Context): live queries to the data warehouse when no prior context exists or existing context is stale.
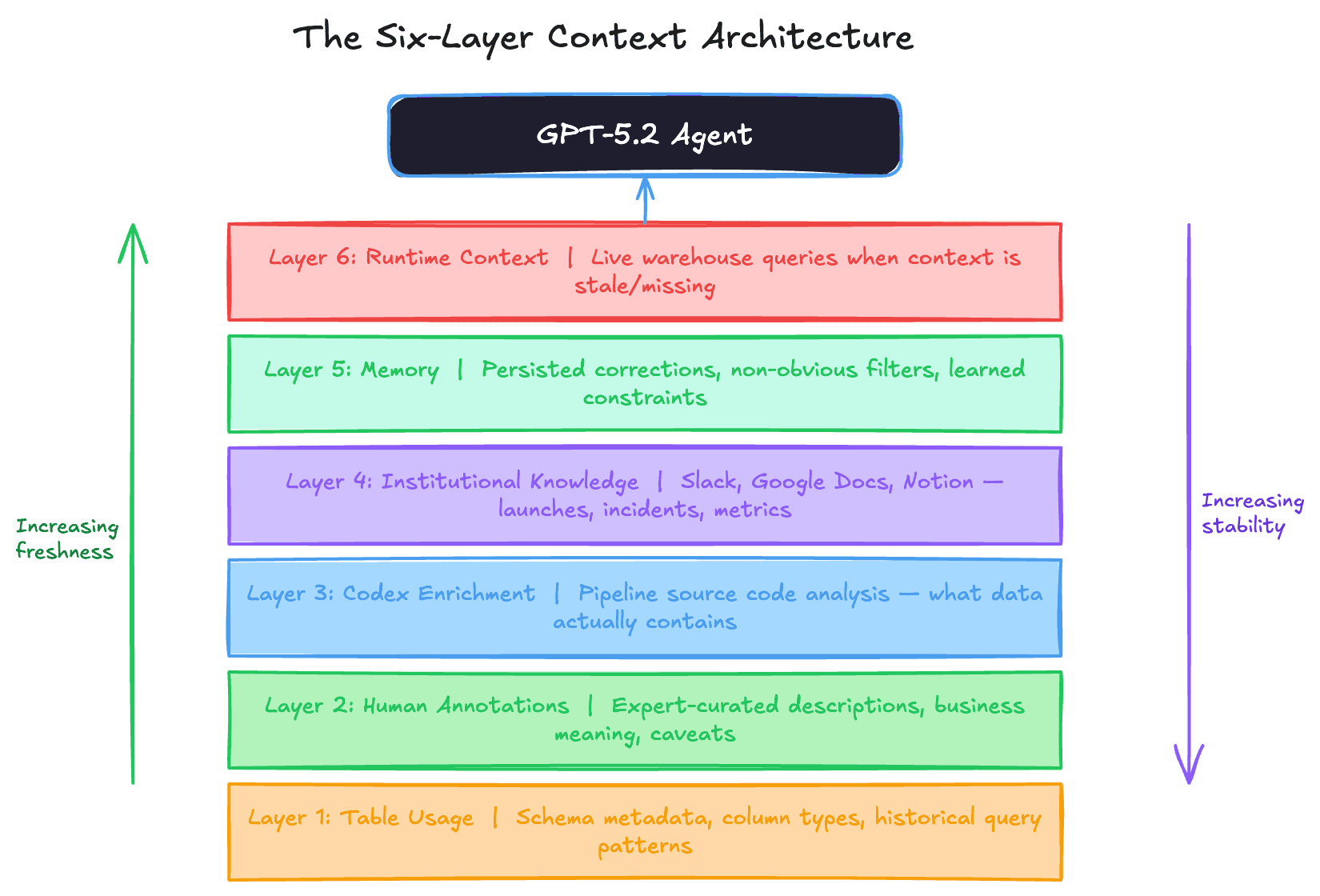
Interview angle: This is a masterclass in RAG architecture design. Interviewers love asking "where does the context come from?" The strong answer layers multiple sources by reliability and freshness: static metadata → human curation → code analysis → organizational knowledge → learned corrections → live data. Each layer compensates for the blind spots of the ones above it.
3.Codex enrichment: meaning lives in code, not schemas
Schema metadata tells you column names and types. Query history tells you how a table is used. But neither tells you what the data actually means. OpenAI uses Codex to crawl the pipeline source code that produces each table, extracting a code-level definition that captures: what transformations are applied, how often the data refreshes, what scope the data covers (e.g., "excludes internal test accounts"), what level of granularity it provides, and how values are computed. This is the key differentiator. Two tables might have identical schemas - same column names, same types - but one excludes logged-out users and the other includes them. That distinction only exists in the ETL code that populates them. By making pipeline logic legible to the agent, Codex enrichment also shows how tables are used beyond SQL - in Spark jobs, Python scripts, and other data systems. This context refreshes automatically as code changes, so it stays current without manual maintenance.
Interview angle: If asked "how would you help analysts distinguish between similar tables?", most candidates say metadata or documentation. The strong answer is: analyze the pipeline code that produces each table. This is the same principle behind data lineage tools like dbt's documentation layer. Interviewers test whether you understand that schema is shape, but code is semantics.
4.Self-learning memory: corrections that persist
Memory is the layer that makes the agent improve over time instead of repeating the same mistakes. When a user corrects the agent - for example, teaching it that a specific analytics experiment requires matching against a particular string in an experiment gate, not a fuzzy match - the agent prompts the user to save that correction. Future conversations start from this improved baseline. Memories are scoped at two levels: global memories apply to all users (e.g., "this table excludes bot traffic"), and personal memories apply only to the individual user (e.g., "when I ask about growth, I mean week-over-week"). Users can also manually create and edit memories. The key design principle is that memory stores non-obvious constraints - the kind of filters and business rules that are critical for correctness but nearly impossible to infer from schemas, code, or documentation alone.
Interview angle: Agent memory is a hot interview topic. The design question is: what should be remembered vs. re-derived? OpenAI's answer: only persist non-obvious corrections that can't be inferred from other context layers. This avoids memory bloat and staleness. Scoping by global vs. personal is also a clean pattern - it maps to the distinction between organizational knowledge and individual preferences.
5.Closed-loop reasoning: self-correcting analysis
The agent doesn't follow a fixed script. It evaluates its own intermediate results and course-corrects. If a SQL query returns zero rows - likely due to an incorrect join or filter - the agent investigates what went wrong, adjusts its approach, and retries. It retains full context across these self-correction loops, carrying learnings forward between steps. This closed-loop process shifts iteration from the user to the agent. Instead of the analyst running a query, eyeballing the results, tweaking the SQL, and repeating, the agent handles that entire feedback loop internally. The agent also handles multi-step analysis end-to-end: understanding the question, exploring relevant data, running queries, and synthesizing findings into a narrative. For ambiguous questions, it proactively asks clarifying questions. If no response comes, it applies sensible defaults (e.g., assuming the last 30 days as the date range) to stay non-blocking.
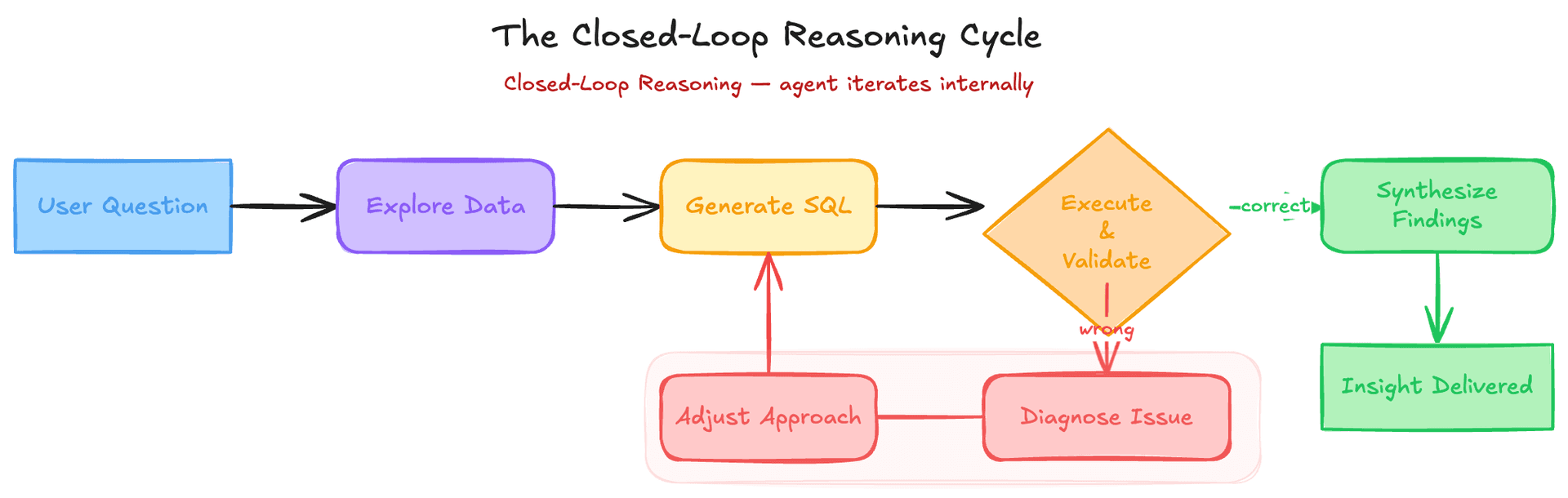
Interview angle: When designing an AI agent, interviewers ask "what happens when it gets something wrong?" The weak answer is "the user corrects it." The strong answer describes a self-correction loop: validate intermediate results, detect anomalies (zero rows, implausible counts), diagnose the root cause, and retry with an adjusted approach - all before surfacing results to the user. This is the ReAct (Reasoning + Acting) pattern in practice.
6.RAG pipeline: embeddings, retrieval, and daily enrichment
A daily offline pipeline aggregates all context layers - table usage, human annotations, and Codex-derived enrichment - into a single normalized representation per table. This enriched context is converted into embeddings using OpenAI's Embeddings API and stored in a vector store. At query time, the agent uses retrieval-augmented generation (RAG): the user's question is embedded, the most relevant table contexts are retrieved via similarity search, and only those contexts are injected into the prompt. This avoids scanning raw metadata across 70k datasets at runtime, keeping latency predictable and low. Runtime queries to the data warehouse are issued separately when the agent needs live data that isn't covered by the pre-computed context - for example, when inspecting a newly created table or validating stale schema information.
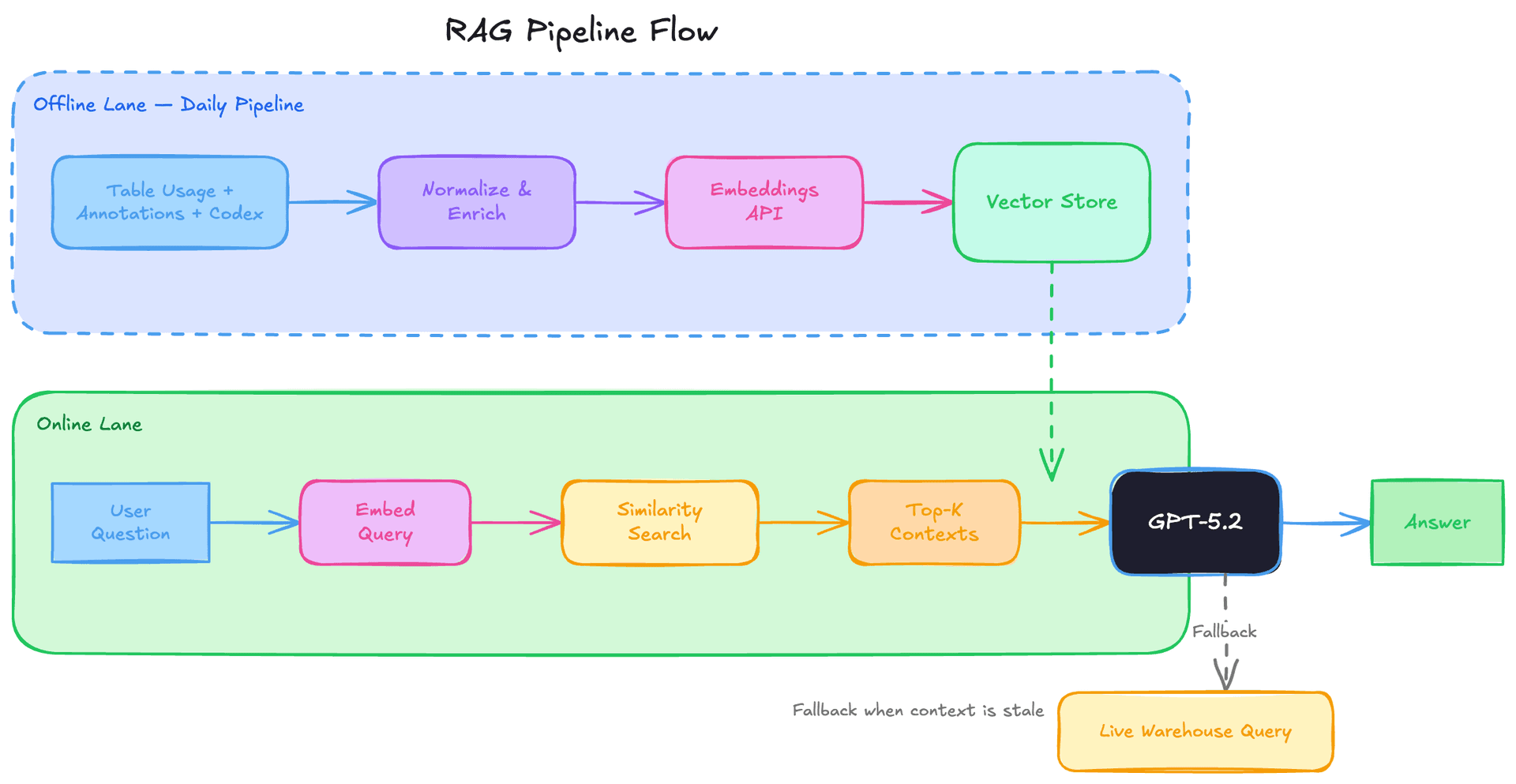
Interview angle: RAG is the most commonly tested LLM architecture pattern. Know the full pipeline: offline enrichment → embedding → vector store → similarity retrieval → prompt injection. The key tradeoff is freshness vs. latency: pre-computed embeddings are fast but can go stale. OpenAI handles this with daily refresh plus a runtime fallback to live queries. When asked "how would you build X with an LLM?", RAG with a freshness strategy is almost always part of the answer.
7.Evaluation: evals as unit tests for agent quality
Quality drift is inevitable in a continuously improving agent. OpenAI uses their Evals API to systematically measure and protect answer quality. The eval suite is built on curated question-answer pairs. Each question targets an important metric or analytical pattern, paired with a manually authored "golden" SQL query that produces the expected result. For each eval run, the agent receives the natural language question, generates SQL, executes it, and the output is compared against the golden SQL's result. Importantly, evaluation doesn't use naive string matching. Generated SQL can differ syntactically while being semantically correct, and result sets may include extra columns that don't affect the answer. Both the SQL and the resulting data are fed into an LLM-based grader that produces a correctness score with an explanation. These evals run continuously in development to catch regressions and serve as canaries in production - functioning exactly like a unit test suite for non-deterministic output.
Interview angle: Agent evaluation is an emerging interview topic. The key insight: you can't string-match LLM output, so you need semantic evaluation. The pattern is: golden input → agent output → execute both → compare results with an LLM grader. This is analogous to snapshot testing in frontend development, but with a semantic comparator instead of a diff. Candidates who mention eval-driven development for AI systems stand out.
8.Security model: pass-through permissions and transparency
The agent operates as a pure interface layer that inherits the requesting user's existing permissions. It cannot access tables the user doesn't already have permission to query. When access is missing, the agent flags it or falls back to alternative datasets the user is authorized to use. Institutional knowledge retrieved from Slack, Google Docs, and Notion goes through a retrieval service that handles access control and caching at runtime - ensuring the agent never surfaces documents a user shouldn't see. For transparency, the agent exposes its reasoning process: it summarizes assumptions and execution steps alongside each answer, and links directly to underlying query results so users can inspect raw data and verify every step.
Interview angle: Security in AI systems is a growing interview area. The key principle is: the agent should never escalate privileges. Pass-through permissions mean the agent's access is the intersection (not union) of its capabilities and the user's permissions. Interviewers also test for "prompt injection" awareness - can a malicious document in the knowledge base trick the agent into leaking data? Mentioning access-controlled retrieval and result transparency signals security-aware design.
9.Lessons learned: less is more, guide goals not paths, meaning lives in code
Three hard-won lessons from building the agent. First, less is more with tools: early versions exposed the full tool set to the agent, but overlapping functionality confused it. Consolidating and restricting tools reduced ambiguity and improved reliability. Second, guide the goal, not the path: highly prescriptive prompts degraded results. Questions share a general analytical shape but differ enough in detail that rigid instructions pushed the agent down wrong paths. Shifting to high-level guidance and letting the model reason about execution paths produced better results. Third, meaning lives in code: schemas and query history describe shape and usage, but the true meaning of a table - its assumptions, freshness guarantees, and business intent - lives in the pipeline code that produces it. This is why Codex enrichment was the single biggest quality unlock.
Interview angle: These are directly applicable agent design principles. "Less is more with tools" maps to the interface segregation principle - agents perform better with fewer, well-scoped tools than many overlapping ones. "Guide goals, not paths" is the difference between imperative and declarative prompting. "Meaning lives in code" applies to any data catalog or metadata system design. Use these as concrete principles when asked "how would you build a reliable AI agent?"
Key Concepts
Retrieval-Augmented Generation (RAG)
An architecture where an LLM retrieves relevant context from an external knowledge store (via embeddings and similarity search) before generating a response. This grounds the model's output in actual data rather than relying solely on its training knowledge, dramatically reducing hallucinations.
Analogy: Like an open-book exam: instead of answering from memory alone, you first look up the relevant reference material, then write your answer. The quality of your answer depends on both your reasoning ability and the quality of what you looked up.
Embeddings
Dense vector representations of text (or other data) that capture semantic meaning. Similar concepts end up close together in vector space. Used for similarity search: embed the user's question, then find the stored documents whose embeddings are closest to it.
Analogy: Like GPS coordinates for meaning. Two restaurants might have different names and addresses, but if they're both "Italian fine dining in downtown," their semantic coordinates are close together.
Data Lineage
The end-to-end trail of how data flows through a system: where it originates, what transformations are applied, and where it ends up. Upstream lineage tracks where a table's data comes from; downstream lineage tracks what depends on it. Critical for understanding data quality and impact of changes.
Codex Enrichment
Using an AI code-understanding model (Codex) to analyze the source code of data pipelines and extract semantic information about what each table contains, how it's computed, and what constraints apply. Goes beyond schema metadata to capture business logic embedded in code.
Analogy: Like reading the recipe instead of just looking at the ingredient list. The ingredients (schema) tell you what's in the dish, but the recipe (pipeline code) tells you how it was prepared, what was left out, and why.
Closed-Loop Reasoning
An agent architecture where the agent evaluates its own intermediate outputs, detects errors or anomalies, and self-corrects before presenting final results to the user. Shifts the debugging and iteration loop from the human to the agent.
Analogy: Like a chef who tastes the dish while cooking and adjusts seasoning, rather than serving it to the customer and waiting for feedback to know if something is off.
Agent Memory
A persistence layer where an AI agent stores corrections, learned constraints, and non-obvious rules from previous interactions. Scoped at global (applies to all users) and personal (applies to one user) levels. Prevents the agent from repeating known mistakes across sessions.
Pass-Through Permissions
A security model where the agent inherits and enforces the requesting user's existing access controls. The agent can never access resources the user can't access directly, ensuring no privilege escalation occurs through the AI layer.
Analogy: Like a personal assistant who can only open doors you've given them your keycard for. They can't get into rooms you're not authorized to enter, no matter how persuasive the request.
Eval-Driven Development
Using curated evaluation suites (question-answer pairs with golden outputs) to measure and protect AI agent quality. Evals run continuously like unit tests, catching regressions before they reach production. Uses semantic comparison rather than string matching since correct AI outputs can differ syntactically.
Knowledge Check
10 questions — your answers are saved locally so you can come back anytime.