Scaling PostgreSQL to power 800 million ChatGPT users
OpenAI runs ChatGPT for 800 million users on a single-primary PostgreSQL instance with ~50 read replicas - no sharding. Over the past year, database load grew 10x. This post covers every optimization they made to keep it running: connection pooling, cache stampede prevention, workload isolation, rate limiting, and safe schema management.
Ready to ace your system design interview?
This article is just one piece. SWE Quiz gives you structured, interview-focused practice across every topic that comes up in senior engineering rounds.
- 1,000+ quiz questions across system design and ML/AI
- Spaced repetition to lock in what you learn
- Full case study walkthroughs of real interview topics
- Track streaks, XP, and progress over time
TL;DR
- Single-primary PostgreSQL + ~50 read replicas serves 800M users and millions of QPS - sharding was deliberately avoided due to complexity.
- PostgreSQL's MVCC copies entire rows on every update, causing write amplification and "dead tuple" bloat that requires careful autovacuum tuning.
- Write-heavy workloads are migrated to Azure CosmosDB; no new tables are allowed in PostgreSQL - new features default to sharded systems.
- PgBouncer connection pooling cut average connection time from 50ms to 5ms; cache stampede prevention ensures a single cache miss doesn't flood the DB.
- Multi-layer rate limiting (app → pooler → proxy → query), workload isolation by priority tier, and cascading replication (in testing) complete the architecture.
Why this matters for interviews
Database scaling is one of the most tested system design topics. This post gives you real production numbers and specific tradeoffs from one of the most trafficked services in the world. Use these as concrete anchors when asked how you'd scale reads, handle write bottlenecks, prevent cascading failures, or design for high availability.
Breakdown
1.The architecture: single primary + ~50 read replicas
OpenAI's PostgreSQL runs as one primary instance that handles all writes, with nearly 50 read replicas distributed across multiple geographic regions. The replicas stay synchronized by streaming a log of changes (the WAL) from the primary. Most read traffic is routed to replicas; the primary is protected and reserved mainly for writes and read queries that must be part of a write transaction. Despite load growing 10x in a year, they chose not to shard - splitting the database across multiple servers would have required changing hundreds of application endpoints and could have taken months or years.
Interview angle: When an interviewer asks "would you shard?", this is the counter-argument: if your workload is read-heavy, replicas can give you enormous headroom before sharding becomes necessary. The cost of sharding existing application code is often underestimated. Know when to reach for each tool.
2.MVCC: why PostgreSQL struggles with high write volumes
PostgreSQL uses MVCC (Multi-Version Concurrency Control) to let multiple transactions read and write at the same time without locking each other out. The tradeoff: when you update even a single field in a row, PostgreSQL doesn't modify the row in place - it copies the entire row to create a new version. Old versions (called "dead tuples") accumulate in the table until a background process called autovacuum cleans them up. Under heavy write loads, this creates write amplification (more bytes written than changed), read amplification (queries must scan past dead tuples to find live data), and table/index bloat.
Interview angle: MVCC is the core reason PostgreSQL doesn't scale writes as well as purpose-built distributed databases. If an interviewer asks about PostgreSQL write limitations, MVCC is the right answer. Also know that autovacuum can be blocked by long-running transactions - a classic ops footgun.
3.Offloading writes: migrating to sharded systems
For workloads that can be horizontally partitioned - typically data that maps cleanly to a user ID, tenant, or region - OpenAI migrates them off PostgreSQL to Azure CosmosDB. They also banned adding new tables to PostgreSQL entirely. All new features must use the sharded systems. This is a "strangler fig" approach: you don't rewrite everything at once, you identify the highest-write workloads, migrate them first, and let the legacy DB's scope shrink over time. The primary also gets protected with strict write rate limits during backfills to prevent write storms.
Interview angle: This is a classic incremental migration pattern. In interviews, when asked how you'd reduce load on an overloaded database, migration + write rate limiting are both strong answers. Mentioning "no new tables on the legacy system" signals that you think about governance and not just immediate fixes.
4.Connection pooling with PgBouncer
PostgreSQL has a hard connection limit (5,000 at OpenAI's scale). Each connection consumes memory, and establishing a new one takes ~50ms due to authentication and setup overhead. PgBouncer is a lightweight proxy that sits between the application and PostgreSQL. Applications connect to PgBouncer (cheap), and PgBouncer multiplexes them onto a small pool of real database connections. In transaction pooling mode - the most efficient - a real DB connection is only held during an active transaction, then returned to the pool. This dropped connection setup time from 50ms to 5ms and eliminated connection exhaustion incidents. Each read replica gets its own Kubernetes deployment of PgBouncer pods behind a load balancer.
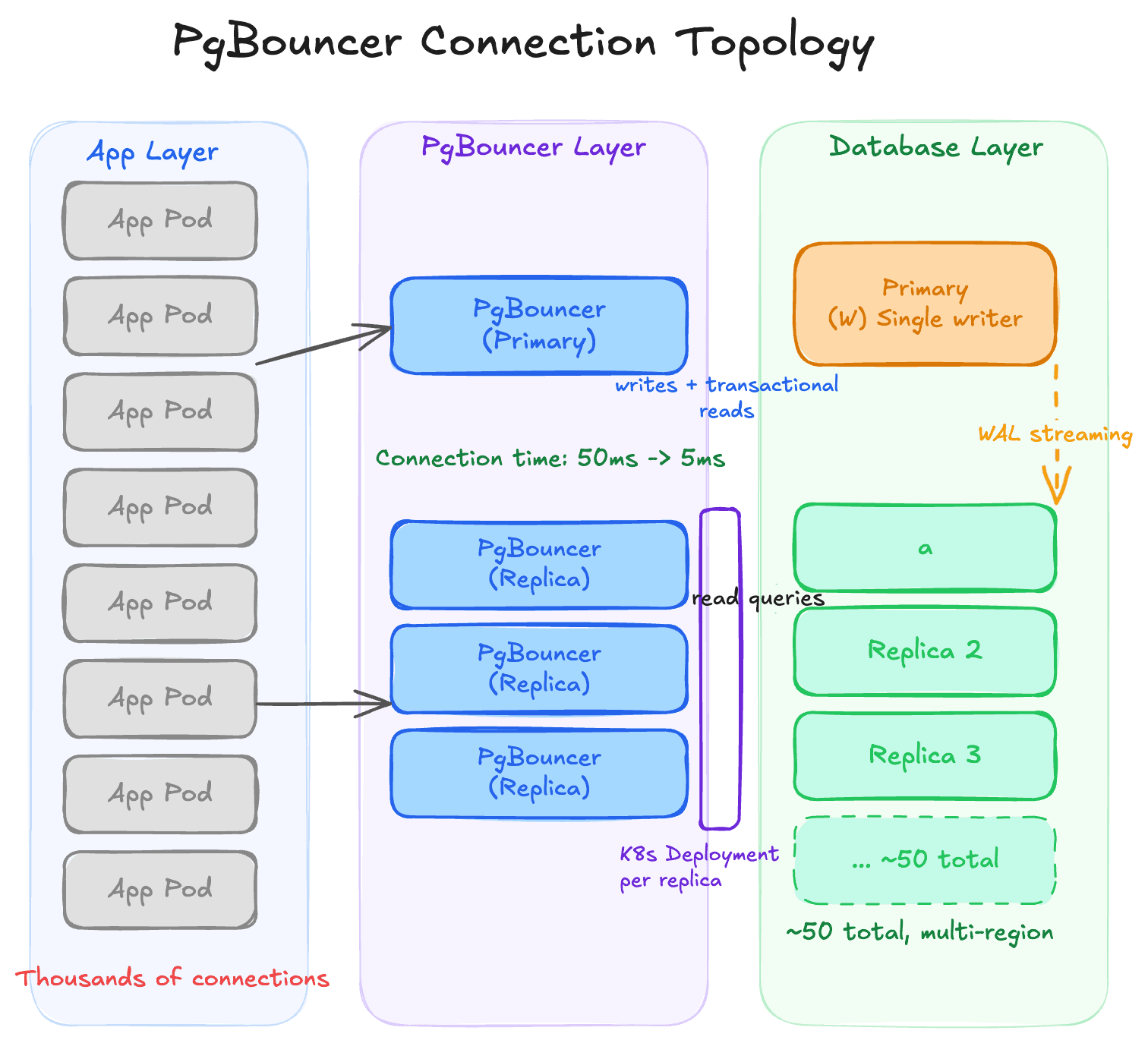
Interview angle: Connection pooling is almost always the right answer when designing a database access layer at scale. Know the three PgBouncer modes: session pooling (one DB connection per app session), transaction pooling (returned after each transaction, best for most use cases), and statement pooling (returned after each statement, incompatible with multi-statement transactions).
5.Cache stampede protection
OpenAI uses a caching layer (think Redis) to serve most read traffic. But caching creates a hidden failure mode: if the cache layer fails or a high-traffic key expires, all pending requests simultaneously miss the cache and hit the database - a "cache stampede" or "thundering herd." The surge can saturate CPU in seconds. Their fix: a distributed lock/lease mechanism on cache misses. When multiple requests miss on the same cache key, only one request acquires the lock and fetches from the database. The rest wait for the cache to be repopulated rather than all hitting the DB in parallel. This turns a potential N-request DB spike into a single DB query.
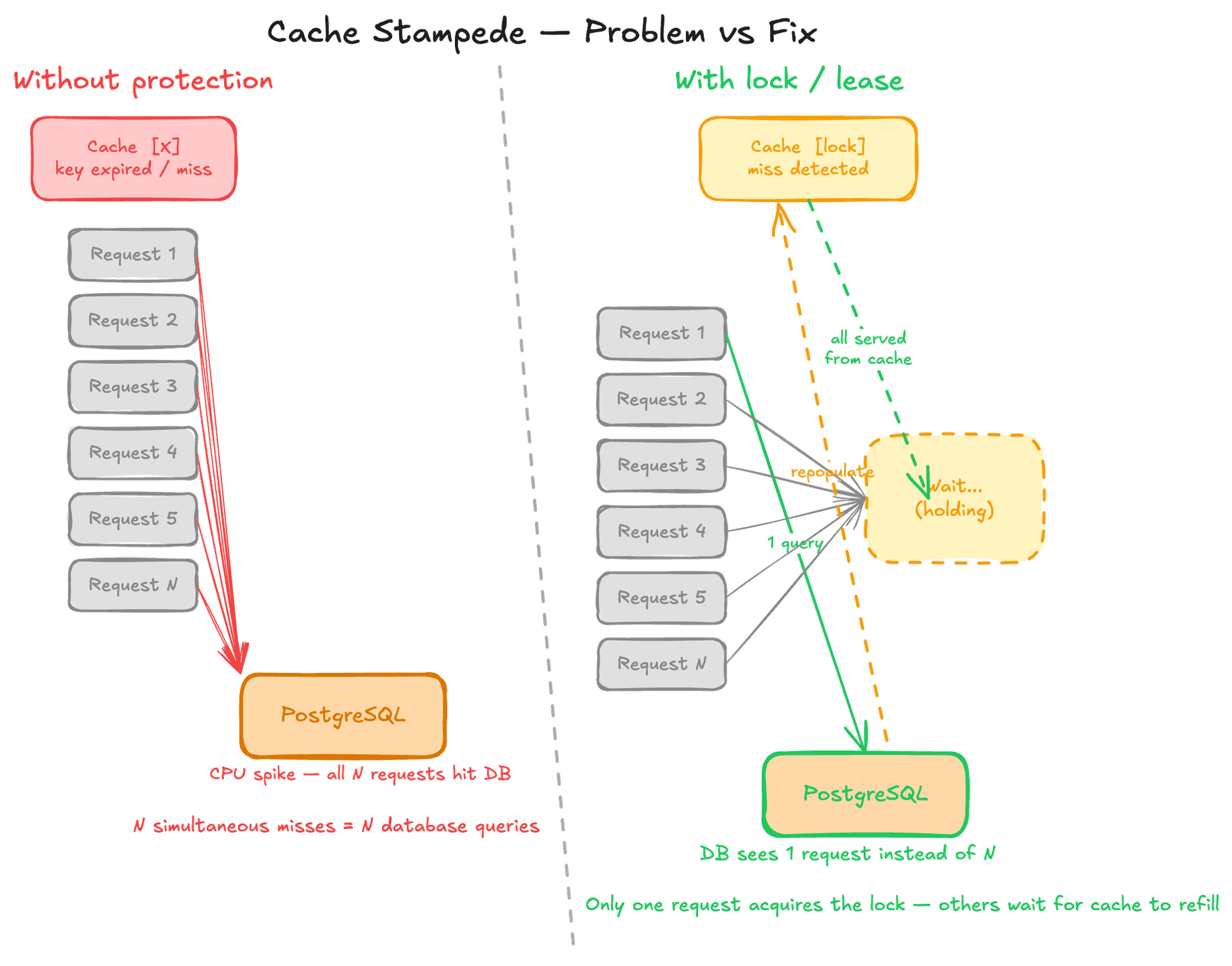
Interview angle: Cache stampede is the most common follow-up after "use a cache." The naive answer to caching is just "add Redis." The strong answer describes cache stampede scenarios and the mutex/lease pattern to prevent them. Other mitigations worth mentioning: cache warming before deploys, staggered TTL expiry, and probabilistic early expiration.
6.Workload isolation: solving the noisy neighbor problem
When multiple features or products share the same database replica, an expensive query from one feature can consume enough CPU and I/O to degrade response times for everything else. OpenAI's solution: route traffic to separate replica instances based on priority. High-priority traffic (e.g., serving active ChatGPT requests) gets its own replicas. Low-priority traffic (e.g., background analytics) gets separate instances. Different products are also isolated from each other so a traffic spike in one product can't impact another.
Interview angle: The noisy neighbor problem comes up any time shared infrastructure is involved - databases, queues, caches, and compute clusters all exhibit it. In interviews, workload isolation via separate instances or namespaces is a clean answer. It's also directly relevant to multi-tenancy design.
7.Multi-layer rate limiting and load shedding
Rate limiting is applied at four layers: the application code, the connection pooler (PgBouncer), the network proxy, and at the query level. At the query level, OpenAI can block specific query "digests" - essentially fingerprints of expensive query patterns - when they start consuming too many resources. This targeted load shedding lets the system recover from a sudden surge of expensive queries without taking down the whole service. They also configured retry logic carefully to avoid retry storms, where failed requests immediately retry and double the load.
Interview angle: Multi-layer rate limiting is the sophisticated answer to "how do you handle traffic spikes?" Most candidates only mention API gateway rate limiting. Query-level load shedding is a particularly strong detail - it shows you understand that database overload is often caused by a specific query pattern, not uniform traffic.
8.Safe schema changes and high availability
In PostgreSQL, even a small schema change like altering a column type can trigger a full table rewrite, locking the table and blocking all reads and writes for minutes on a large table. OpenAI's rules: only lightweight schema changes are allowed (adding/dropping columns that don't rewrite the table), a 5-second hard timeout is enforced on all schema changes, and indexes must be created with `CONCURRENTLY` (which builds without locking). All new tables must go to the sharded system, not PostgreSQL. For high availability, the primary runs with a hot standby - a fully synchronized replica that is promoted instantly if the primary fails. Multiple replicas per region ensure a single replica failure doesn't cause a regional outage.
Interview angle: Schema migration safety is an area where junior engineers often underestimate risk. Knowing about `CREATE INDEX CONCURRENTLY`, the expand/contract migration pattern, and column-level vs. table-level locks signals production experience. Hot standby vs. warm standby vs. cold standby is a standard HA question.
Key Concepts
MVCC (Multi-Version Concurrency Control)
PostgreSQL's concurrency model. Instead of locking a row during an update, it creates a new version of the row alongside the old one. Readers see the old version until the transaction commits. The old versions ("dead tuples") must be cleaned up by autovacuum.
Analogy: Like a Google Doc with tracked changes that are never accepted - the document keeps growing with all old versions until someone runs "accept all changes."
WAL (Write-Ahead Log)
A sequential log of every change made to the database, written before the change is applied to the actual table data. PostgreSQL uses it for crash recovery (replay the log after a crash) and replication (stream the log to replicas so they can replay it and stay in sync).
Analogy: A ship's captain's log: every action is recorded in order before it's considered official. If the ship sinks (crash), you can reconstruct what happened from the log.
Read Replicas
Copies of the primary database that stay synchronized via WAL streaming. They can serve read queries, distributing read load across many machines. They cannot handle writes - all writes must go to the primary.
Analogy: Multiple printed copies of a reference book. Anyone can read any copy, but all edits must go to the one original that all copies are printed from.
Connection Pooling
A proxy that maintains a small pool of real database connections and multiplexes many more application connections onto them. Prevents connection exhaustion and eliminates per-connection setup overhead. PgBouncer is the standard PostgreSQL connection pooler.
Cache Stampede (Thundering Herd)
When a cached value expires or the cache restarts, many simultaneous requests all miss the cache and hit the database at once, causing a sudden traffic spike. Prevented by a distributed lock/lease so only one request fetches from the DB and repopulates the cache.
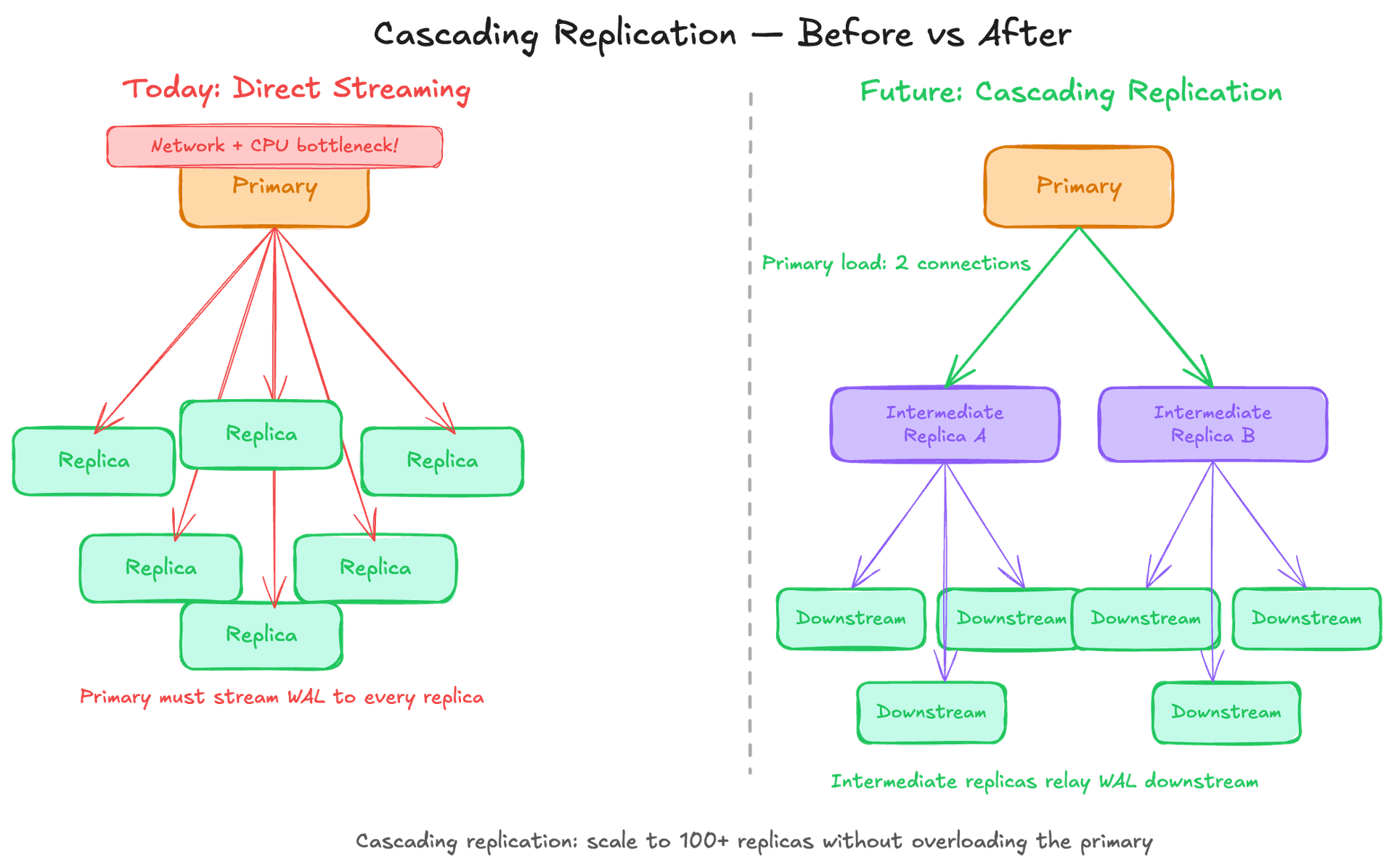
Cascading Replication
Instead of the primary streaming the WAL to every replica directly, intermediate replicas relay the WAL stream to downstream replicas. Reduces the network and CPU load on the primary as the number of replicas grows beyond what the primary can serve directly.
Autovacuum
PostgreSQL's background process that reclaims storage from dead tuples left behind by MVCC. If misconfigured or blocked by long-running transactions, tables accumulate bloat, queries slow down, and indexes grow unnecessarily large.
Hot Standby
A replica that is fully synchronized with the primary and can immediately be promoted to become the new primary if the current primary fails. Contrast with warm standby (synced but not actively serving queries) and cold standby (an offline backup that must be restored).
Knowledge Check
10 questions — your answers are saved locally so you can come back anytime.